- How it works: Applies code-based rules and metrics to check outputs against objective criteria.
- Best for: Objective checks, ground truth comparisons (using datasets), format validation (JSON, regex), safety checks (keyword detection), length constraints.
- Requires: Defining specific rules (e.g., exact match, contains keyword, JSON schema validation) and potentially providing a Dataset with expected outputs.
For subjective criteria, use LLM-as-Judge.
For human preferences, use HITL (Human In The Loop).
Setup
1
Go to evaluations tab
Go to evaluations tab on a prompt in one of your projects.
2
Add evaluation
On the top right corner, click on the “Add evaluation” button.
3
Choose Programatic Rule
Choose “Programatic Rule” tab in the evaluation modal.
4
Choose a metric
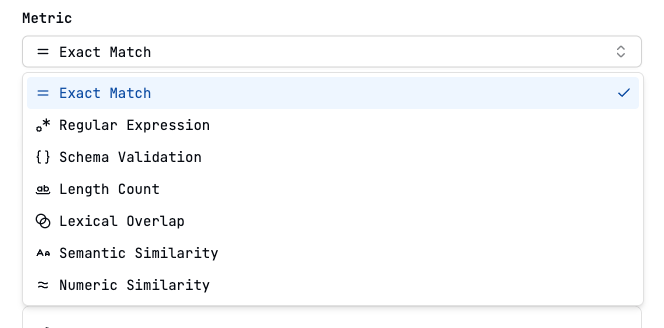
Metrics
Exact Match
Checks if the response is exactly the same as the expected output. The resulting score is “matched” or “unmatched”.
Regular Expression
Checks if the response matches the regular expression. The resulting score is “matched” or “unmatched”.
Schema Validation
Checks if the response follows the schema. The resulting score is “valid” or “invalid”. Right now only JSON schemas are supported.
Length Count
Checks if the response is of a certain length. The resulting score is the length of the response. The length can be counted by characters, words or sentences.
Lexical Overlap
Checks if the response contains the expected output. The resulting score is the percentage of overlap. Overlap can be measured with longest common substring, Levenshtein distance and ROUGE algorithms.
Semantic Similarity
Checks if the response is semantically similar to the expected output. The resulting score is the percentage of similarity. Similarity is measured by computing the cosine distance.
Numeric Similarity
Checks if the response is numerically similar to the expected output. The resulting score is the percentage of similarity. Similarity is measured by computing the relative difference.
Expected output
The expected output, also known as label, refers to the correct or ideal response that the language model should generate for a given prompt. You can create datasets with expected output columns to evaluate prompts with ground truth.Exact Match, Lexical Overlap, Semantic Similarity and Numeric Similarity metrics require expected output.
Using Datasets for Ground Truth
Many programmatic rules (Exact Match, Lexical Overlap, Semantic Similarity) require comparing the model’s output against a known correct answer (expected_output). This is typically done by:
- Creating a Dataset containing input examples and their corresponding desired outputs.
- Configuring the evaluation rule to use the
expected_outputcolumn from that dataset. - Running the evaluation in an experiment on that dataset.