Live example
Overview
This tutorial demonstrates how to build a quality assurance system for customer support responses using three specific Latitude evaluation types:- LLM-as-Judge: Rating evaluation for helpfulness assessment
- Programmatic Rules with Exact Match for required information validation
- Human-in-the-Loop manual evaluation for customer satisfaction scoring
The Prompt
This is the prompt that will be used to generate customer support responses. It is a simple prompt that takes a customer query and generates a response. It doesn’t use a knowledge base or any additional information.The Evaluations
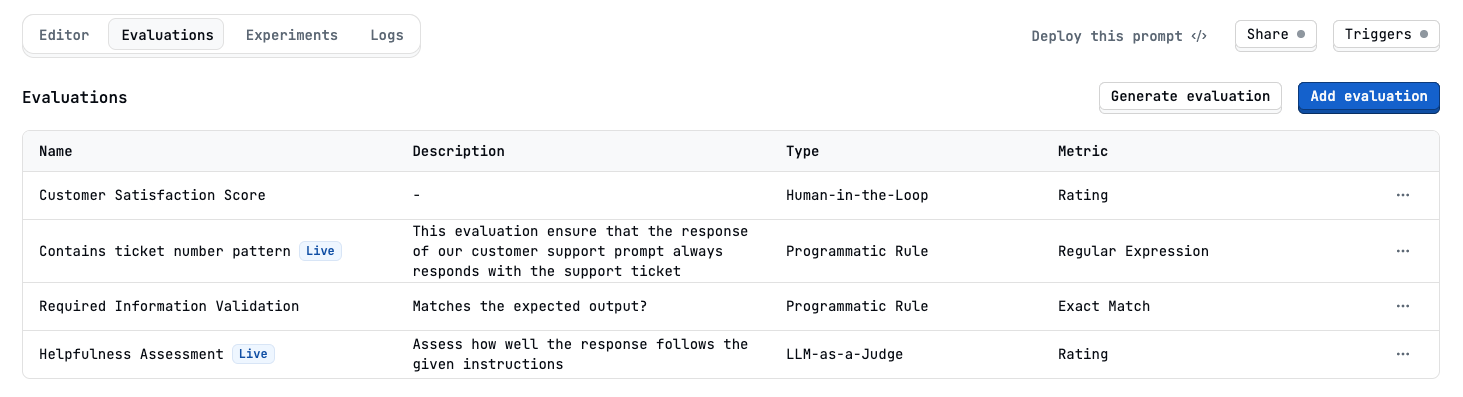
To create new evaluations, go to the evaluations tab in the Latitude Playground and click on “Add Evaluation”.
Helpfulness Assessment (LLM-as-Judge)
Helpfulness Assessment (LLM-as-Judge)
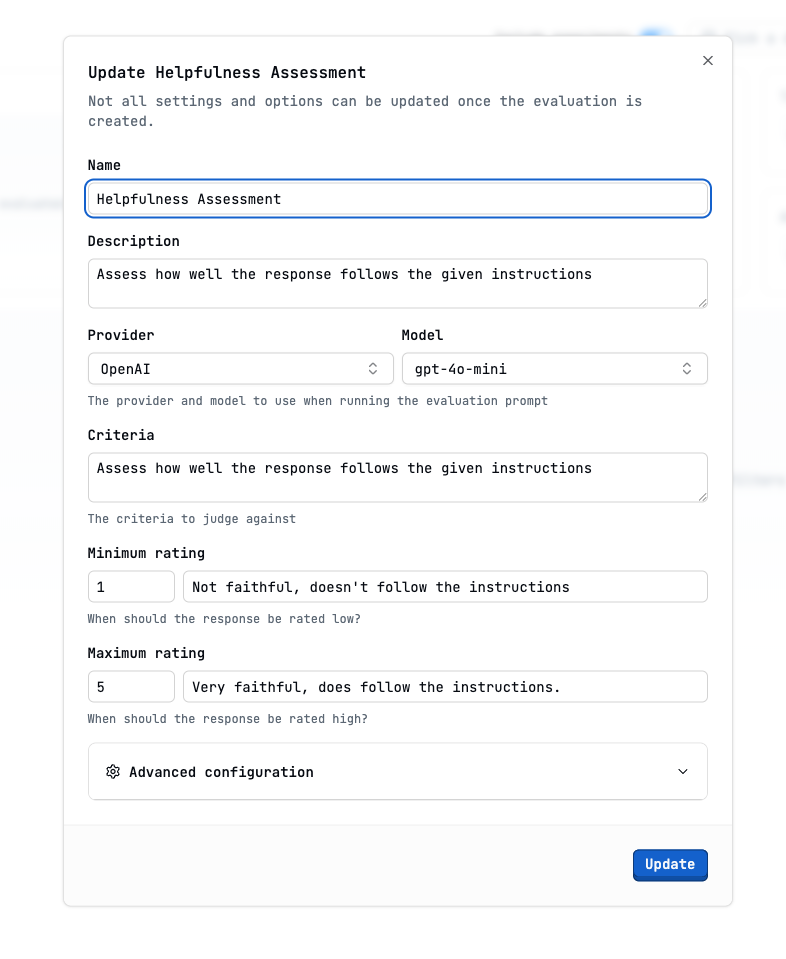
Configure the evaluation
Show LLM-as-Judge Evaluation modal image
Show LLM-as-Judge Evaluation modal image
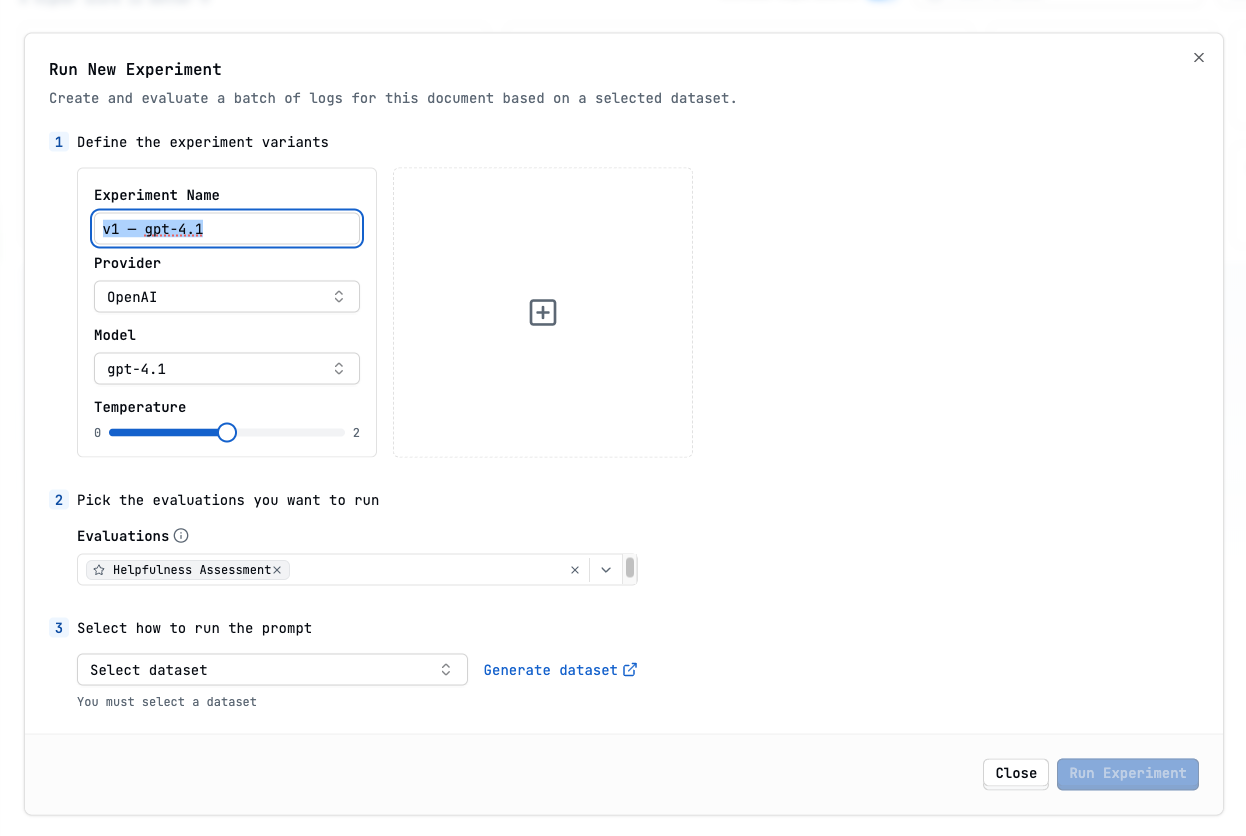
Create an experiment from the evaluation
Show Experiment modal image
Show Experiment modal image
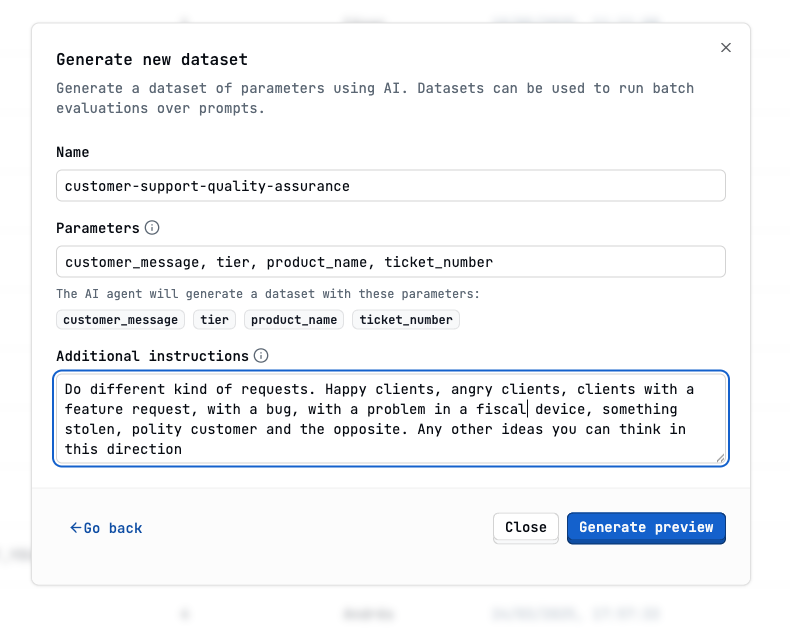
Create the synthetic dataset
Show Generate dataset modal image
Show Generate dataset modal image
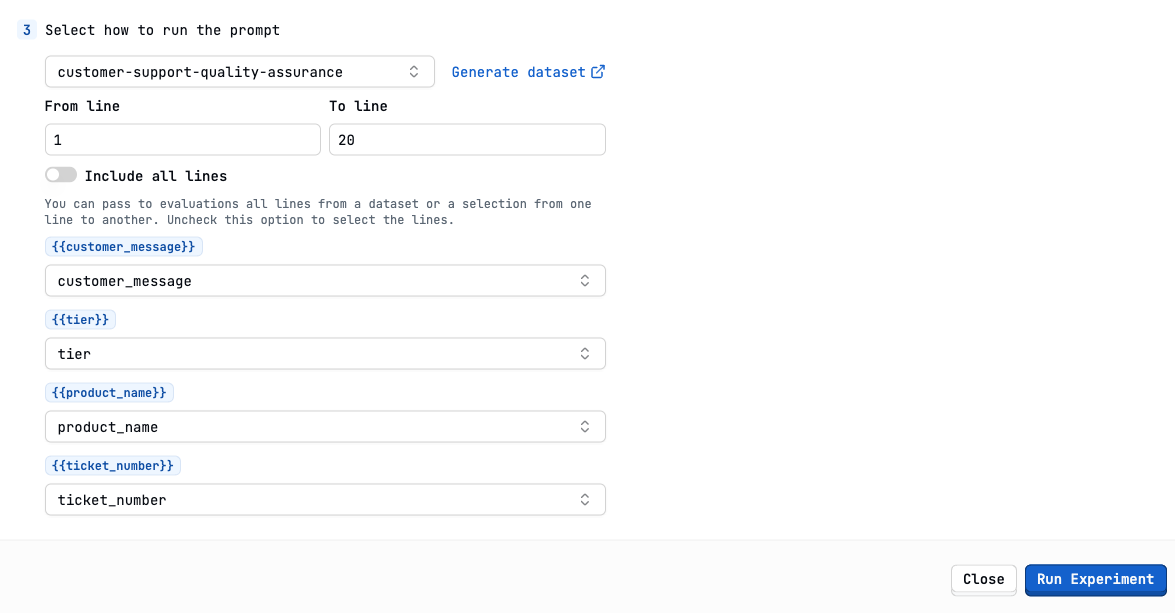
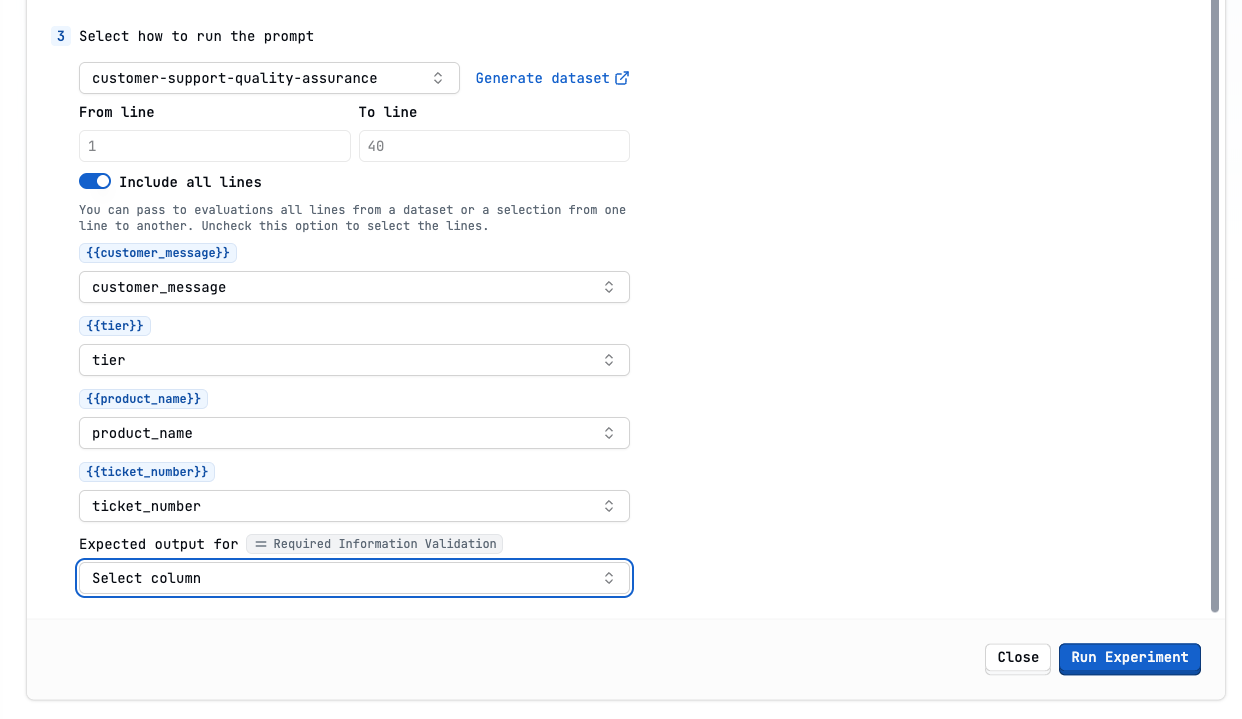
Run the experiment
Show Select dataset in experiment image
Show Select dataset in experiment image
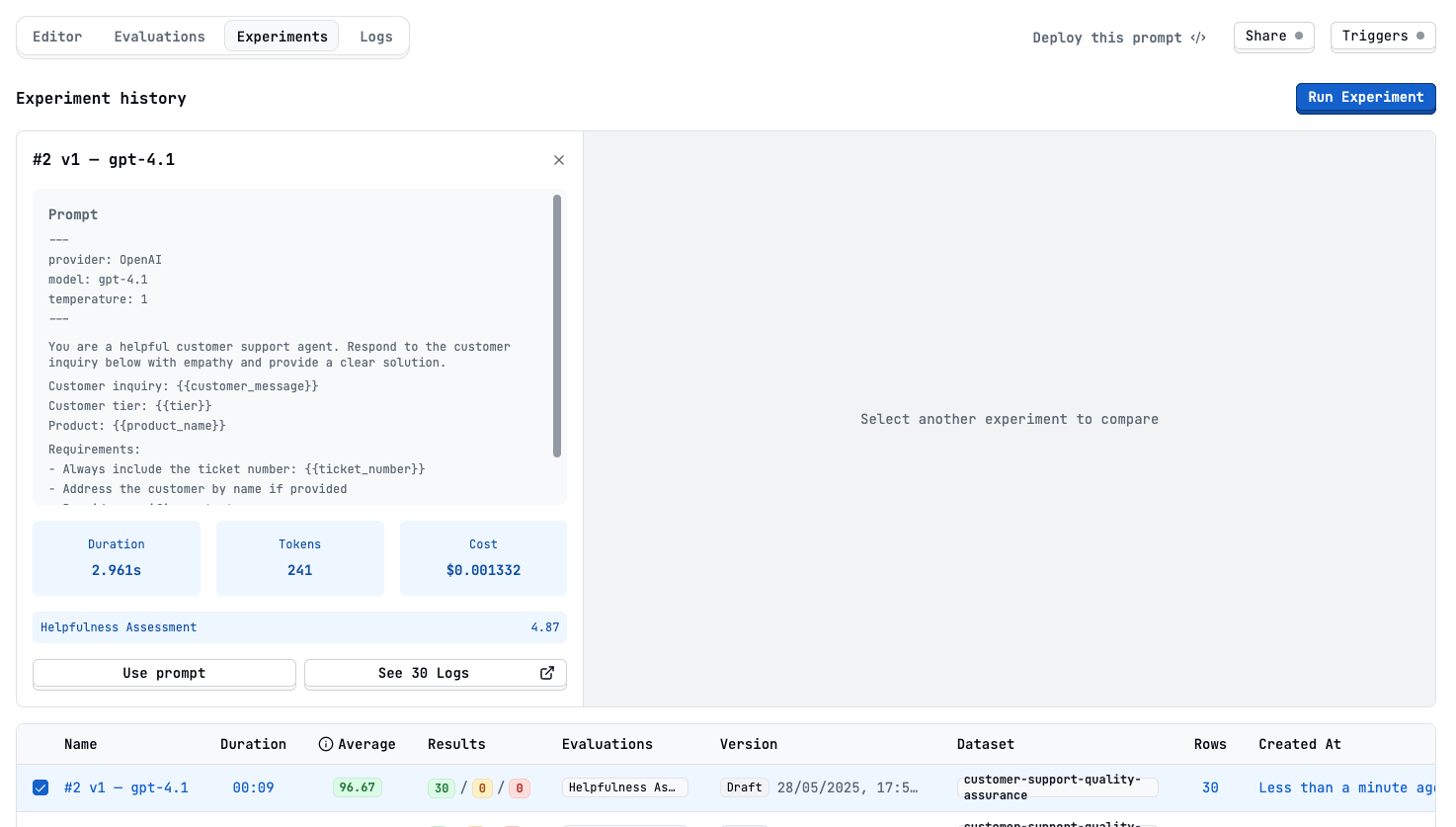
View experiment results
Show Experiment results image
Show Experiment results image
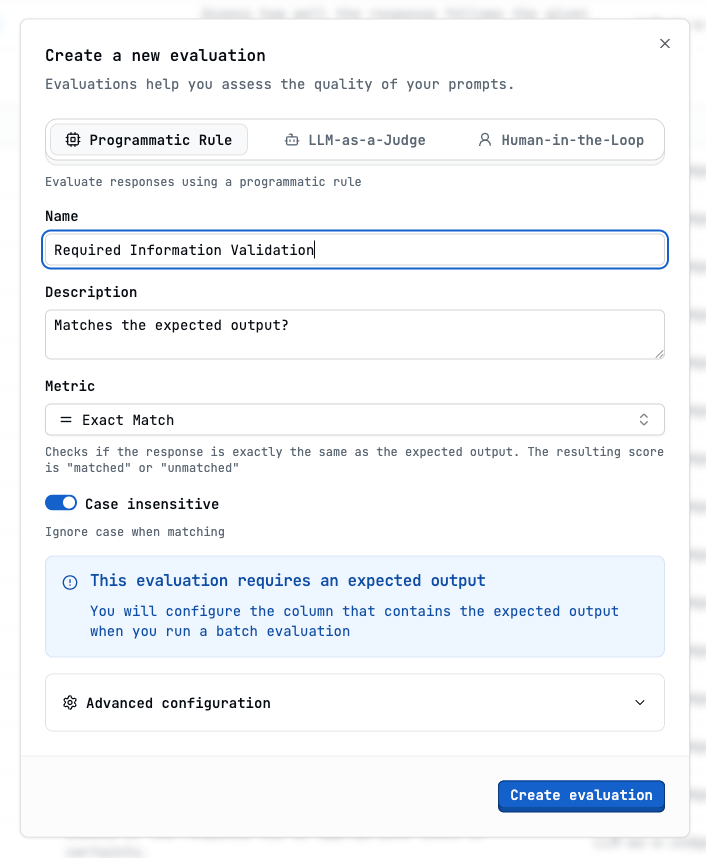
Required Information Validation (Programmatic Rule - Exact Match)
Required Information Validation (Programmatic Rule - Exact Match)
Configure the evaluation
Show Programmatic rule Evaluation modal image
Show Programmatic rule Evaluation modal image
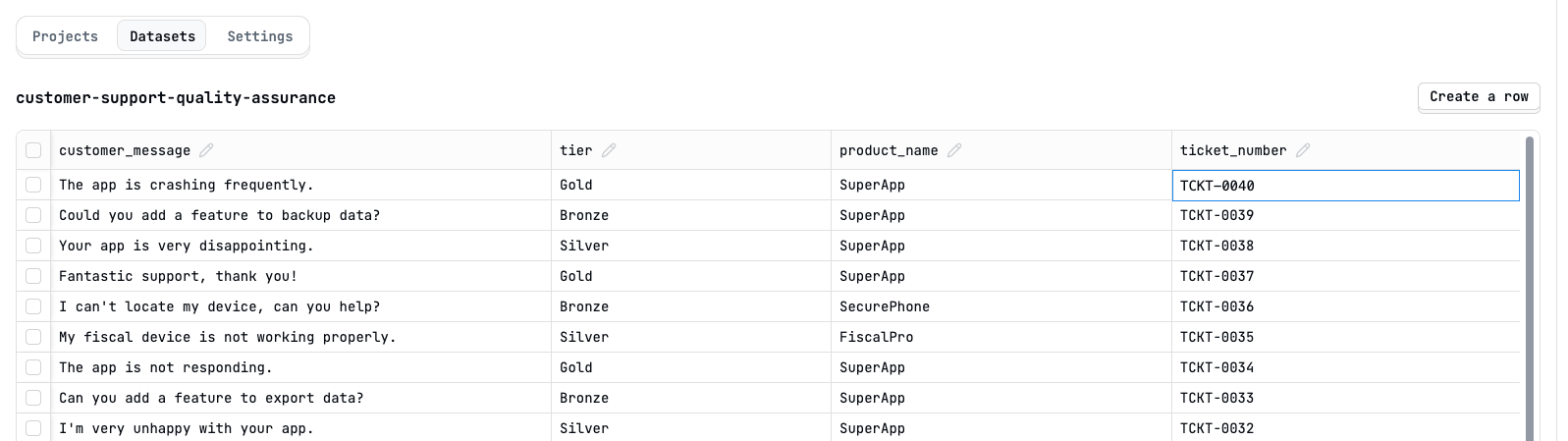
Create dataset with expected output
Show Dataset with expected output selector image
Show Dataset with expected output selector image
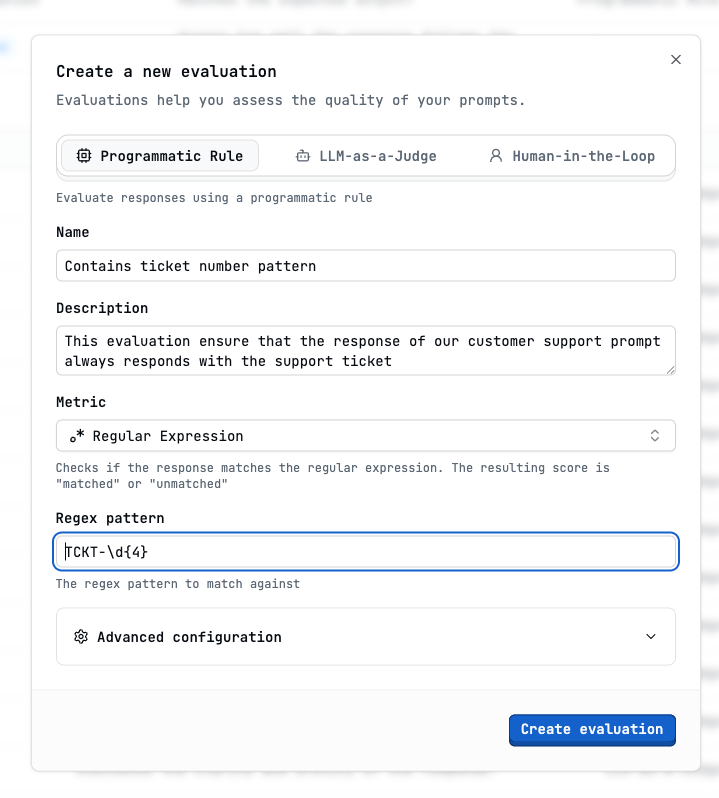
Contains Ticket Number (Programmatic Rule - Regular Expression)
Contains Ticket Number (Programmatic Rule - Regular Expression)
Configure the evaluation
- The ticket number starts with
TCKT- - Followed by 4 digits (
-\d{4})
Show Dataset ticket column image
Show Dataset ticket column image
Show Regular expression Evaluation modal image
Show Regular expression Evaluation modal image
Run the experiment
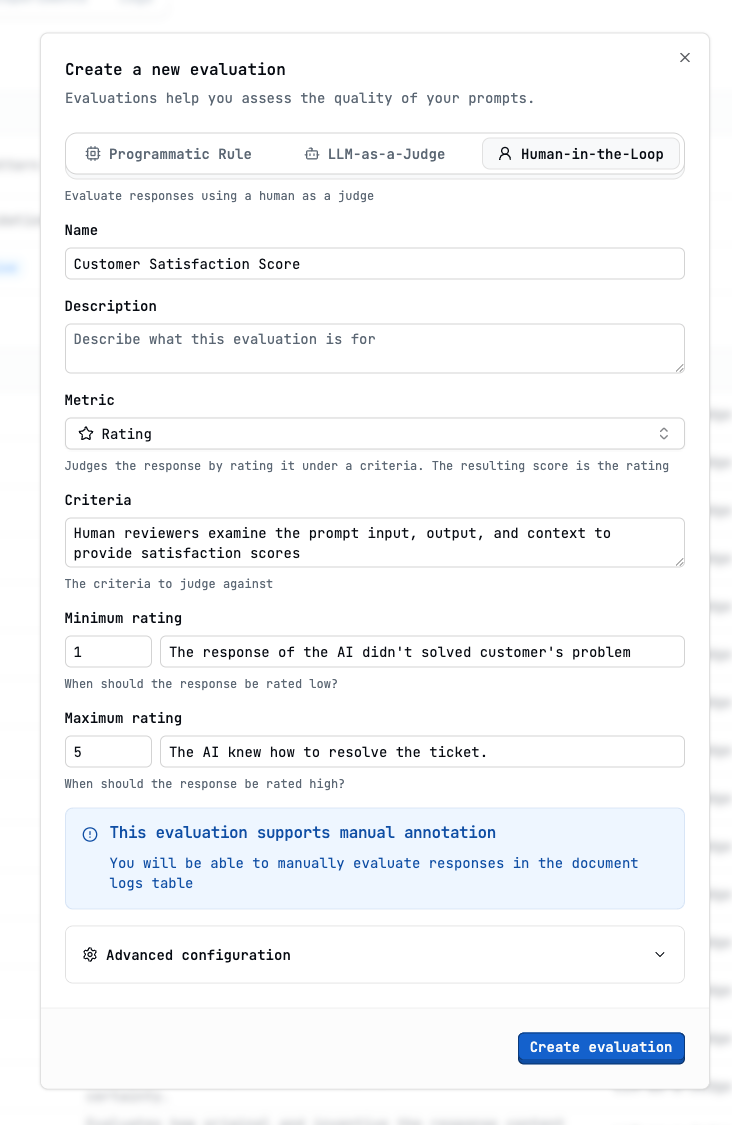
Manual Evaluation (HITL - Human in the Loop)
Manual Evaluation (HITL - Human in the Loop)
Configure the evaluation
Show Manual evaluation modal image
Show Manual evaluation modal image
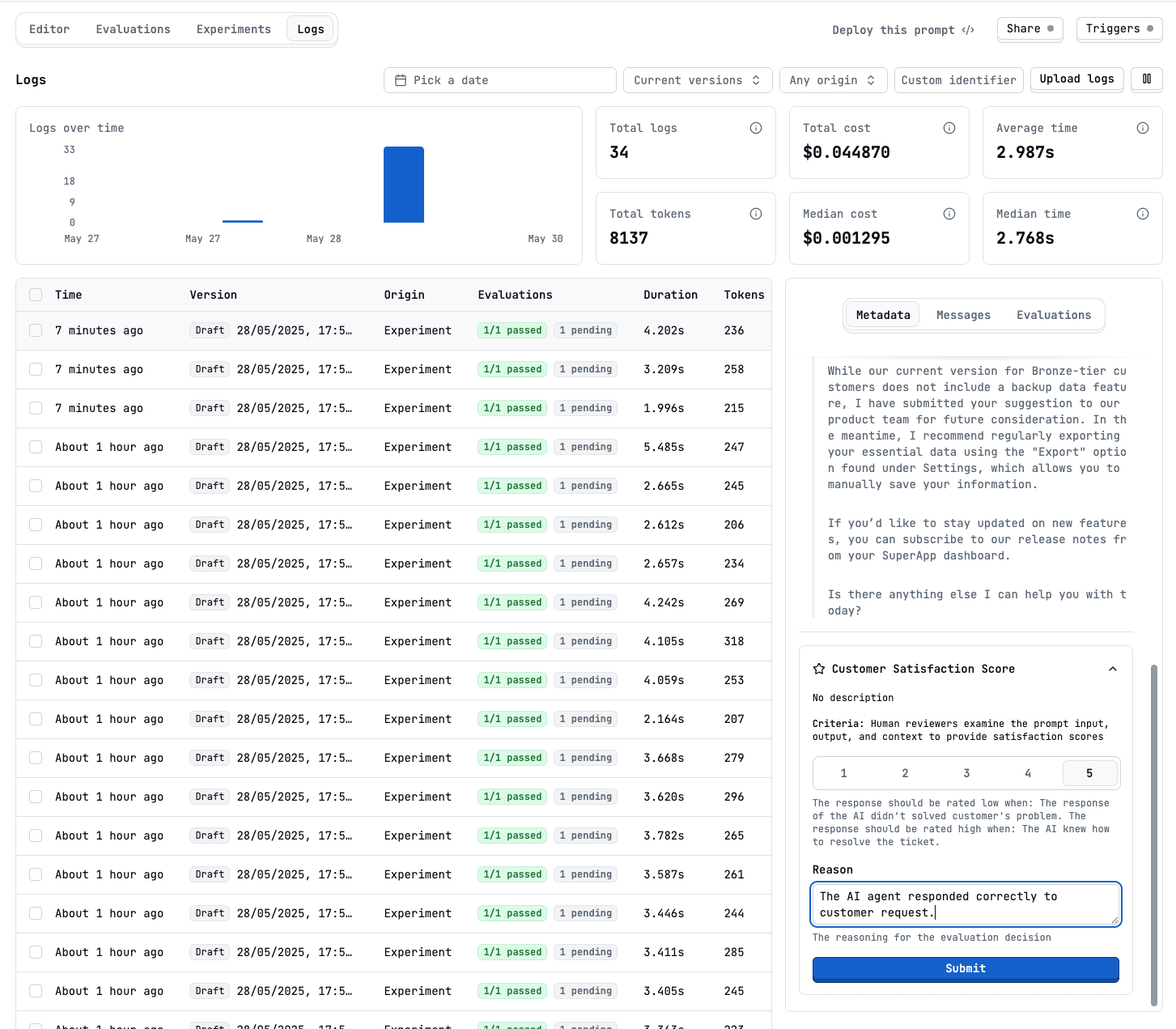
Annotate past conversations (logs)
Show Manual evaluation on latitude logs
Show Manual evaluation on latitude logs
Annotate with the SDK
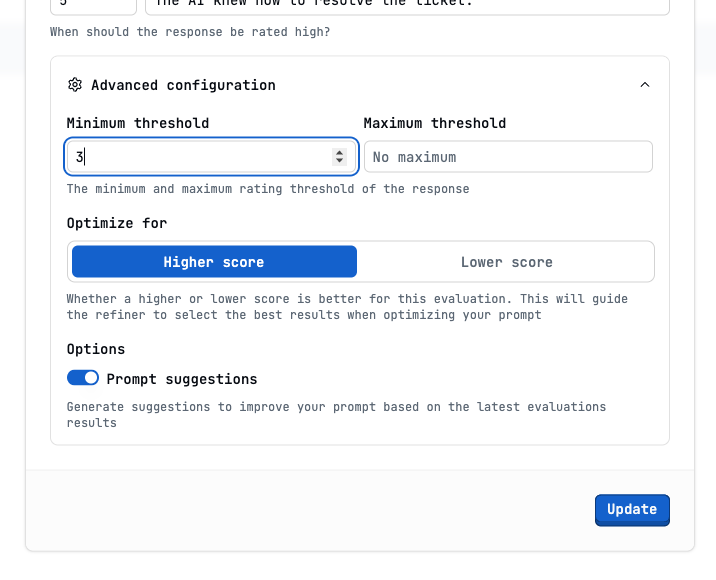
Minimum score
Show Min score configuration
Show Min score configuration
Manual evaluation results
1 but in green. This was before we set the minimum score to 3. The next one didn’t pass and is shown in red.Show Min score configuration
Show Min score configuration
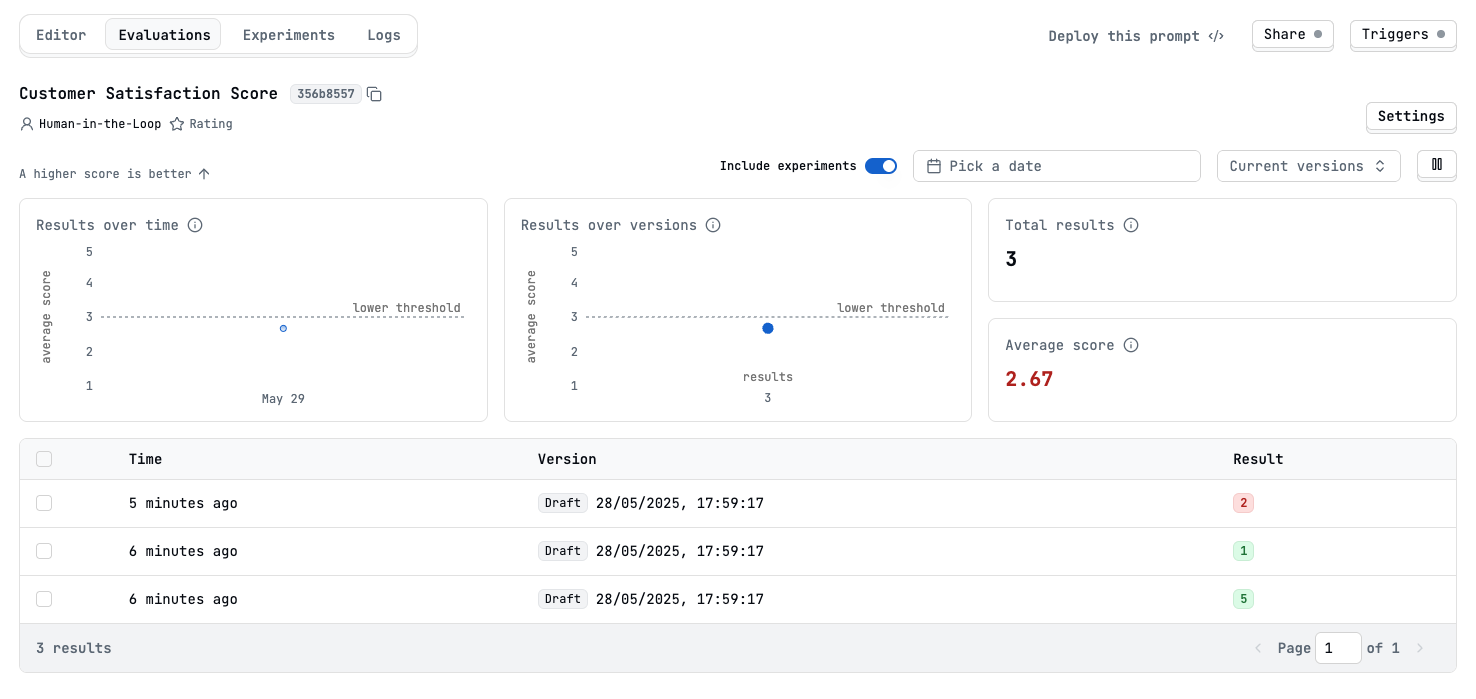
Live Mode
We’ve done a lot of work so far. We set up four types of evaluations but only tested against synthetic data. Now we want to test our evaluations against real customer interactions—this is what we call Live Mode. Let’s set the Helpfulness Assessment evaluation to live mode. Go to the evaluation’s detail, click the top right corner Settings, and at the bottom under Advanced configuration, you can see the Evaluate live logs toggle.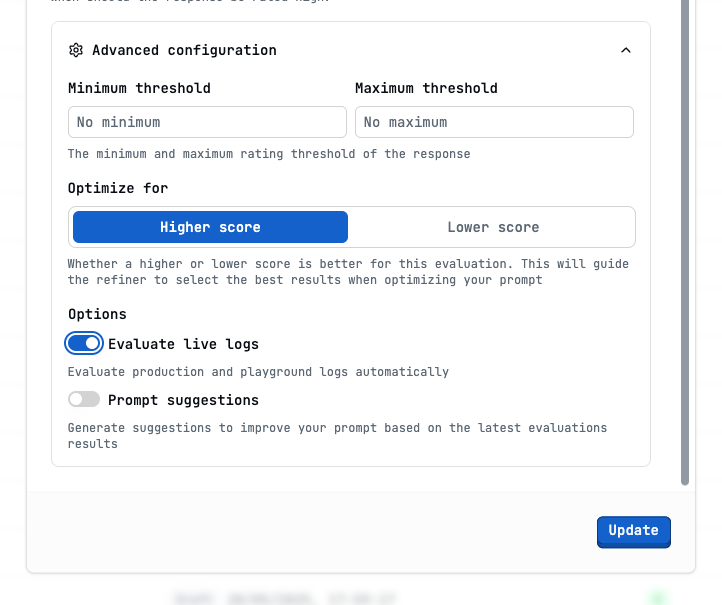
Conclusion
By setting up a robust evaluation framework for customer support responses, we’ve learned how different types of automated and manual evaluations work together to ensure high-quality service. Automated LLM-based ratings help us assess response helpfulness at scale, while programmatic rules—like exact match and regular expressions—ensure critical information such as ticket numbers and required statements are always included. Human-in-the-loop (manual) evaluations provide the nuanced judgment that only real people can offer, especially for customer satisfaction and tone. Testing our system with both synthetic and real data (live mode) gives us confidence that our evaluations are both reliable and effective. Ultimately, these evaluations help us catch issues early, improve our AI prompts, and consistently deliver accurate and customer-friendly support—leading to better customer satisfaction and operational excellence.Resources
- LLM-as-Judge Evaluation — How to use LLMs to evaluate responses
- Programmatic Rule Evaluation — How to use programmatic rules to evaluate responses
- Human-in-the-Loop Evaluation — How to use human evaluators to evaluate responses
- Running Evaluations — How to run evaluations against synthetic and live data
- Datasets — How to create datasets for evaluations